Fully Sharded Data Paralell
Date:
Fully Sharded Data Parallel is a kind of DDP(Distributed Data parallel) process. Flavors of data parallelism: - DDP, ZeRO-1(, ZeRO-2 and FSDP(ZeRo-3) Other implementations: - DeepSpeed ZeRO, FairScale’s
From here: GPT models are implemented using minGPT. A randomly generated input dataset is used for benchmarking purposes. All experiments ran with 50K vocabulary size, fp16 precision and SGD optimizer.
| Model | Number of layers | Hidden size | Attention heads | Model size, billions of parameters |
|---|---|---|---|---|
| GPT 175B | 96 | 12288 | 96 | 175 |
| GPT 1T | 128 | 25600 | 160 | 1008 |
DDP vs FSDP:
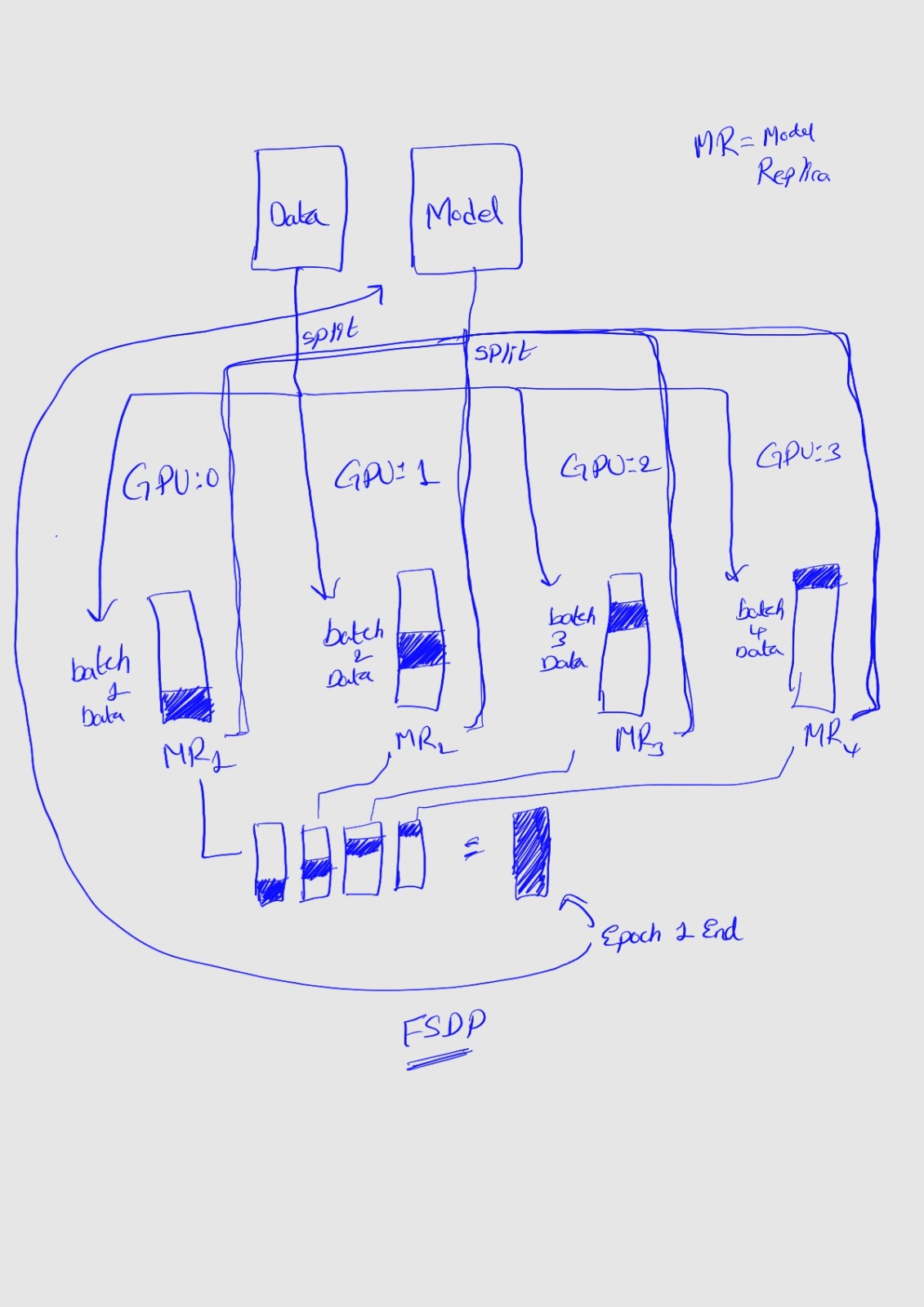
- DDP: each process/ worker owns a replica of the complete model and processes a batch of data, finally it uses all-reduce to sum up gradients over different workers.
- FSDP: is a type of data parallelism that shards model parameters, optimizer states and gradients across DDP ranks and process a batch of data and aggregated at epoch end. FSDP GPU memory footprint would be smaller than DDP across all workers.
In DDP each process holds a replica of the model, so the memory footprint is higher compared to FSDP that shards the model parameter, optimizer states and gradients over DDP ranks. The peak memory usage using FSDP with auto_wrap policy is the lowest followed by FSDP and DDP.
Notes below is from the youtube series: we are going to use torch elastic, using torchrun , which will set the worker RANK(single GPU id) and WORLD_SIZE(total GPUs count) automatically.
t5_auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
T5Block,
},
)
In the above block T5Block holds both MHSA+FFN i.e Multi Head Self Attention and Feed Forward Networks. So in any network Block that holds Both Attention and Feed forward layers is important. we found GPT2Block in modeling gpt2.py file here.
# for other models:
from deep_vit import Residual
from cross_vit import PreNorm
from cait import LayerScale
from transformers.models.t5.modeling_t5 import T5Block
from transformers.models.gpt2.modeling_gpt2 import GPT2Block
# many other blocks here:
https://huggingface.co/transformers/v4.9.2/_modules/index.html
Mixed Precision: 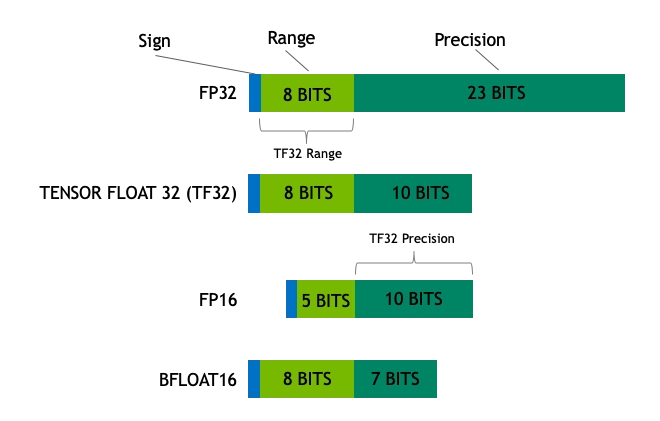
Mixed precision in FSDP: 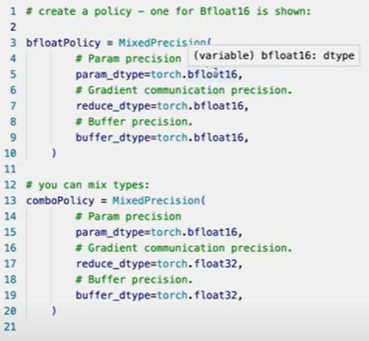
Details:
- batch norm is automatically kept in fp32 for precision (overrides buffer policy, no user action needed).
- local gradients during backprop are also always fp32 (automatic, no user action needed.)
- Models are always saved in fp32 for max probability.

The above automatically checks bf16 native and GPU support.
ShardingStrategy:
ShardingStrategy.SHARD_GRAD_OP ## Zero2
ShardingStrategy.FULL_SHARD ## Model+optimizer+gradient
ShardingStrategy.NO_SHARD ## goes to DDP Mode
Architecture:
Model replicas with only part of the parameters in run.