Discovering emerging product badges at scale with llms
Published:
We built a batch pipeline that helps data teams surface newly introduced product badges across large e-commerce corpora before XPath rules and CSS selectors silently break. The LLM does not replace the crawler — it classifies a small set of candidate lines discovered cheaply across the store.
The architecture below was validated on multi-retailer product-detail page (PDP) corpora at production scale. The same deduplication, pre-filtering, and candidate-classification pattern applies to badges, urgency labels, and other short, repeated merchandising text.
Why Product Badges Matter
Most e-commerce engineering effort goes into stable extraction:
- Product titles
- Pricing
- Inventory
- Ratings
- Images
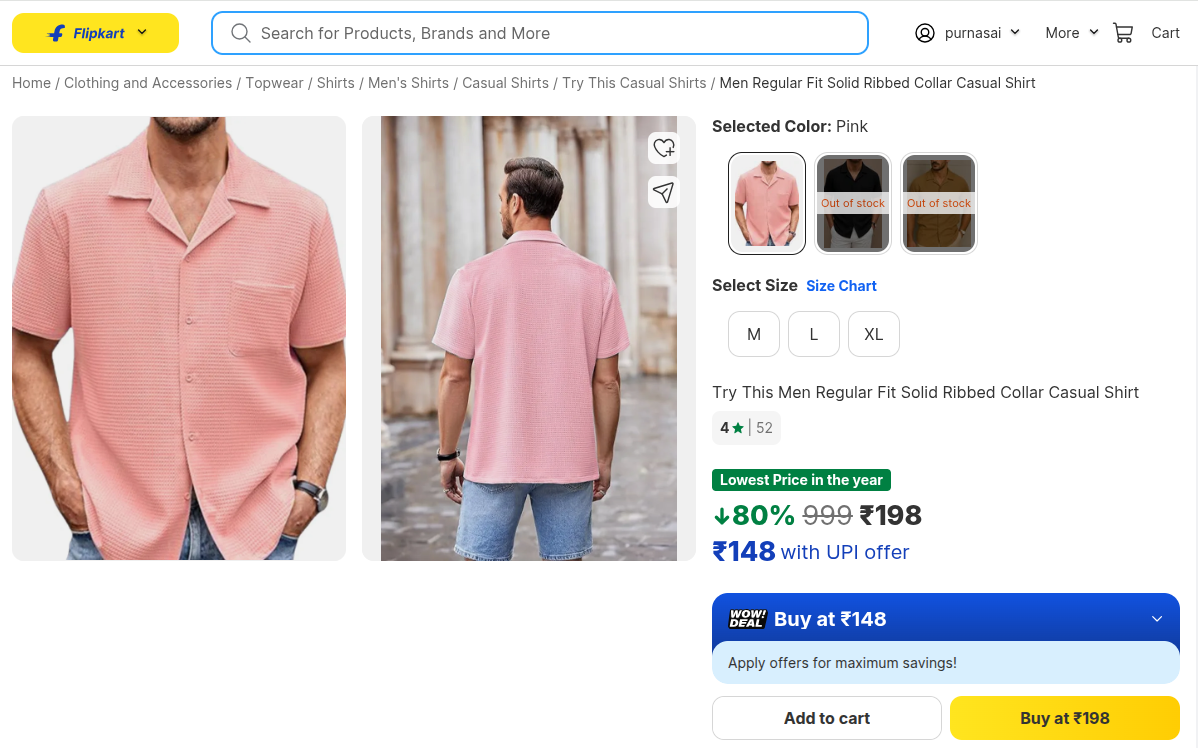
Shoppers also respond to small merchandising signals on the page:
- Best Seller
- Trending
- New Arrival
- Limited Stock
- Only 3 Left
- Most Loved
- Hot Sale
These badges drive measurable behavior:
| Signal type | Example | Effect |
|---|---|---|
| Trust | “Best Seller” | Social proof — other buyers validated the product |
| Urgency | “Only 2 Left” | Scarcity — act now instead of deferring |
| Discovery | “New Arrival” | Recency — recently launched assortment |
| Conversion | Seasonal labels (“Hot Sale”) | Merchandising experiments on CTR and add-to-cart |
For product intelligence platforms, badges are not cosmetic UI. They are structured attributes that analysts, pricing teams, and search relevance systems consume — when extraction keeps up.
The Engineering Problem
Stable fields vs. evolving merchandising text
Traditional crawl pipelines assume relatively stable DOM patterns:
- Product name in
<h1>or JSON-LD - Price in a known widget
- Availability in stock APIs or predictable spans
Badges break that assumption. Retailers continuously:
- Introduce new badge copy (“Best Seller” → “Customer Favorite”)
- Redesign badge components (pill → ribbon → icon + alt text)
- Move labels between PLP tiles, PDP hero, and recommendation carousels
- Run seasonal campaigns with one-off badge language
When layout shifts, extraction rules fail before anyone notices:
- XPath and CSS selectors return empty nodes
- Manual store configs drift out of date
- Data quality drops; root cause is discovered weeks later
Scale makes manual discovery impossible
At one retailer, a badge like “Trending” may appear on hundreds or thousands of SKUs within days. Across dozens of retailers, no team can manually diff page HTML fast enough to keep badge catalogs current.
The question we set out to answer:
How do we automatically discover previously unseen badge text across tens of thousands of PDPs before production extractors miss it — without sending every page to an LLM?
Design Principle: LLM-Assisted Discovery, Not Extraction
We deliberately separated two concerns:
| Concern | Owner | Output |
|---|---|---|
| Discovery | Batch pipeline + LLM on candidates | “These strings look like new badges; here is evidence” |
| Extraction | Engineers + production crawlers | Durable XPath/CSS/JSON rules per store |
The LLM never runs in the hot path of a live crawl. It runs on deduplicated candidate lines after cheap deterministic filters. Engineers review discoveries, ship rules, and production extraction stays deterministic and auditable.
This framing is important for engineering credibility: we are not claiming an LLM replaces DOM parsing. We are using it where heuristics alone are ambiguous — is this repeated line a badge, navigation chrome, or product copy?
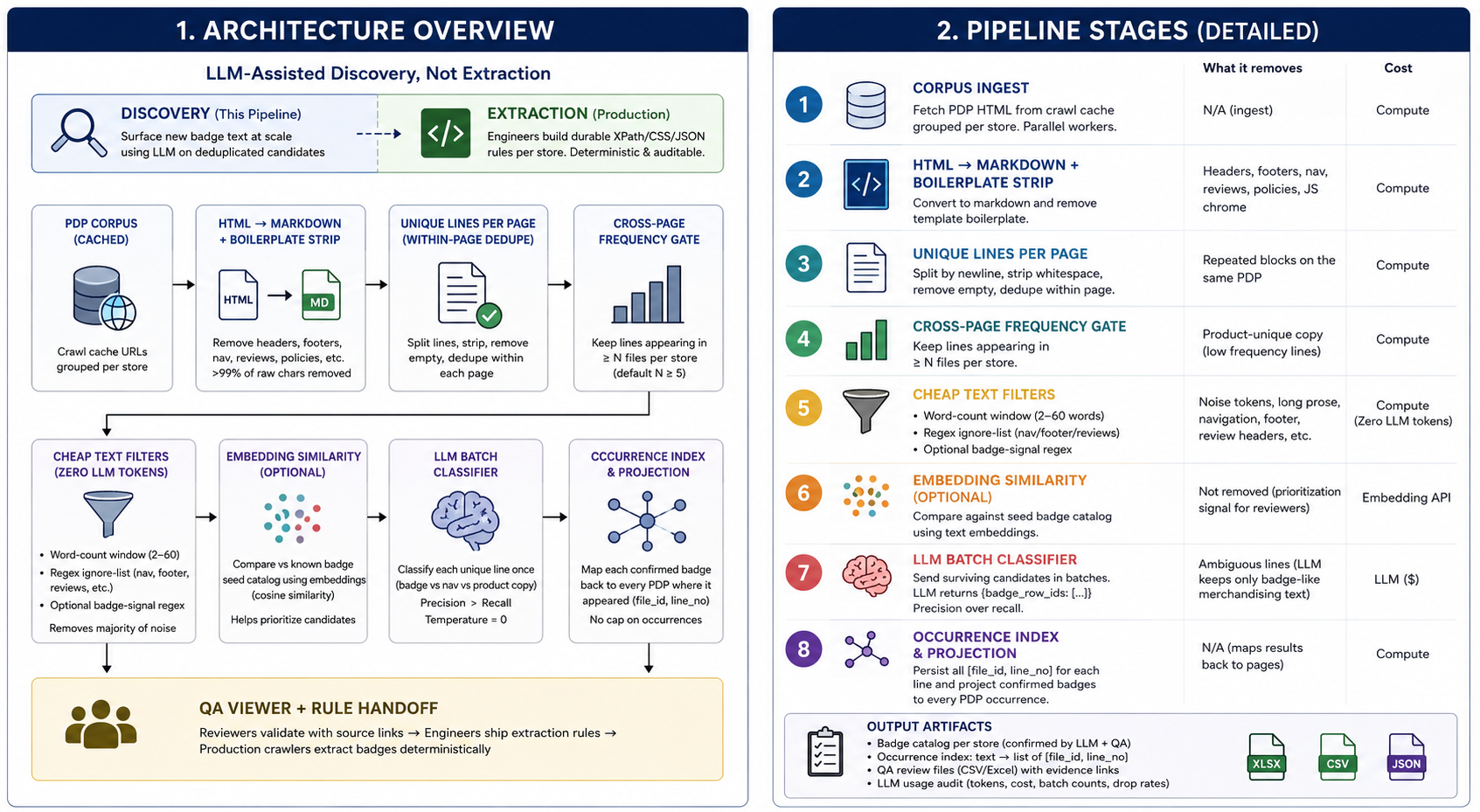
Architecture Overview
PDP corpus (cached)
│
▼
HTML → Markdown + boilerplate strip (>99% of raw chars removed)
│
▼
Per-page unique lines (split, strip, within-page dedupe)
│
▼
Cross-page frequency gate (keep lines appearing in ≥ N files per store)
│
▼
Word-count window + regex ignore-list (zero LLM tokens)
│
▼
[Optional] Embedding similarity vs known badge seed catalog
│
▼
LLM batch classifier (badge vs nav vs product copy)
│
▼
Occurrence index (text → list of [file_id, line_no] across all pages)
│
▼
QA viewer + rule handoff to production extractors
Core insight: If "Best Seller" appears on 400 PDPs, a per-page LLM approach pays for that string 400 times. A corpus-wide approach classifies the string once and projects the label onto all 400 pages via the occurrence index.
LLM cost scales with distinct merchandising language per store, not with SKU count.
Pipeline Stages (Production Shape)
The architecture above maps to eight concrete stages. Each stage is independently tunable — you can tighten frequency thresholds, swap embedding models, or skip the seed-catalog step entirely if you have no prior badge list. The only non-negotiable stage is the occurrence index: without it, you classify text but lose the ability to project results back to specific pages.
1. Corpus ingest
Input is a cohort of PDP URLs (typically from an existing retail crawl cache, not live fetches during the job). Pages are grouped per store — badge vocabulary is store-specific; global deduplication would blur retailer semantics.
Parallel workers fetch HTML and convert to markdown. Raw HTML volume is large; markdown after cleanup is typically under 1% of raw character count.
2. Boilerplate and noise removal
Before line analysis, strip recurring template content:
- Headers, footers, navigation
- Review blocks and star-rating boilerplate
- Long policy paragraphs and JS-rendered chrome
Template detection is imperfect: slight layout drift can leave residual nav text. That is why later stages do not rely on templates alone.
3. Unique lines and within-page deduplication
For each markdown file:
- Split on newlines, strip whitespace
- Skip empty lines
- Deduplicate within the page (same badge repeated in mobile/desktop blocks counts once per file)
Each surviving line is keyed as (store, normalized_text) with metadata:
file_id— stable id for the PDP markdown fileline_no— 1-based line index (for human QA click-through)
4. Cross-page frequency gate
Count how many distinct files contain each line (per store). Keep lines that appear in at least N files (we used N ≥ 5 as a default).
Rationale: Product-specific copy (“Hydrating serum for dry skin”) rarely repeats identically across many PDPs. Store-wide badges and campaign labels do.
This single filter removes the majority of noise before any embedding or LLM call.
5. Cheap text filters (zero LLM tokens)
Apply in order:
- Word-count window (e.g. 2–60 words) — drops single tokens, symbols, and long paragraphs (upper bound is conservatively wide to avoid false negatives; confirmed badges are almost always 2–8 words)
- Regex ignore-list — drops known nav/footer patterns (“Find a Store”, “Privacy Policy”, review headers)
- Optional badge signal regex — short patterns that boost priority (not required for candidacy)
On a representative 1,400-page run, the ignore-list alone eliminated ~57% of remaining candidates before the LLM.
6. Embedding similarity against a seed catalog (optional)
Maintain a workbook or JSON list of known badge labels (“Best Seller”, “New”, “Selling Fast”, …). Embed candidate lines and seed labels with a text embedding model; keep pairs above a cosine threshold.
This step does not replace discovery — it tags lines similar to known badges and helps reviewers prioritize. New badge copy with no seed match still flows through if it passes frequency gates.
Implementation note: in-memory cosine over batch embeddings is sufficient at our scale; a vector database is optional, not mandatory.
7. LLM batch classifier
Send surviving candidates in batches (e.g. 50–100 lines per request). System prompt defines badge narrowly:
Count as badge: short merchandising labels conveying status, scarcity, popularity, or recency on a product — typically adjacent to product identity on PDP or listing tiles.
Do not count: navigation, legal, reviews, size/shade names, section headers without merchandising meaning, markdown table noise.
Model returns JSON: { "badge_row_ids": [ ... ] } — precision over recall.
We run at temperature 0 and retry failed batches. Token usage and USD cost are logged per job for audit.
8. Occurrence index and projection
For every candidate line, persist the full list of [file_id, line_no] pairs — no cap on occurrences (UI may show capped examples; export uses the full index).
When the LLM marks line "Only 2 left" as a badge:
- Store one classification row for the text
- Join to the occurrence index
- Emit one output row per PDP where the line appeared
Reviewers get evidence links; engineers get a deduplicated badge catalog per store run.
How We Got Here: Three Iterations
We did not jump straight to corpus deduplication. The evolution is itself a useful lesson for similar problems.
v1 — Per-page LLM on a stratified sample
Approach: Stratified sample (~1,000 PDPs) across categories. Convert each page to markdown; send page text (or chunks) to a frontier model (Claude Sonnet class); ask for badge-like phrases.
Result: High recall on obvious badges; useful for proving the problem.
Cost driver: Tokens ∝ pages × average page length. The same “Trending” string is re-analyzed on every page it appears on.
Rough economics: ~$20 per 1K-page sample run at Sonnet-class pricing.
Lesson: Per-page LLM is a good prototype, bad production discovery engine.
v2 — Boilerplate strip + example-driven retrieval
Approach: Aggressive template removal (header/footer/nav). Build a retrieval step using a seed set of known badge strings: embed pages or line windows, retrieve chunks similar to seed badges, then LLM on retrieved spans only.
Result: Lower token volume than v1; better focus than whole-page prompts.
Pain points:
- Template matchers break when DOM shifts slightly — residual boilerplate pollutes candidates
- Retrieval still surfaces near-duplicate lines many times across chunks
- Hybrid retrieval (dense + sparse) adds moving parts (index build, chunk boundaries)
Rough economics: ~$13 per comparable 1K-page cohort — better, but still tied to redundant text.
Lesson: Retrieval helps localization; it does not fix corpus-level duplication.
v3 — Unique-line corpus + occurrence map (current design)
Approach:
- Extract all unique lines per store corpus with file + line presence
- Apply frequency and ignore-list filters deterministically
- Classify each unique line once with a smaller open-weight model (e.g. 120B-class OSS model via hosted inference)
- Project confirmed badges to all files via the occurrence index
Result: Stable batch jobs from 1K-page pilots to ~100K-page full-store corpora without sampling.
Cost driver: Tokens ∝ unique candidate lines after filters, not pages.
Rough economics:
| Scale | Pages | Unique candidates (post-freq) | Lines to LLM | Total LLM cost |
|---|---|---|---|---|
| Pilot (capped) | 1,399 | 2,156 | 916 | ~$0.02 |
| Full cohort | 31,055 | 71,013 | 27,820 | ~$0.31 |
| Steady-state ops | 100,000+ | grows sublinearly | filtered tail | cents per day at OSS-model rates |
Compare to v1-style per-page cost at ~$0.014/page: ~960× cheaper at 1.4K pages, ~1,400× cheaper at 31K pages. The savings ratio increases with scale because deduplication and ignore-lists absorb more growth as the corpus grows.
Lesson: For repeated short text, invert the loop — aggregate first, classify second, project third.
Prototype per-page, production per-line. v1 validated that the task was solvable with an LLM. v3 validated that the economics were acceptable at scale. Both steps were necessary.
Pre-Filters Before the LLM (Checklist)
Engineering teams can copy this ordering:
| Stage | What it removes | Cost |
|---|---|---|
| HTML → markdown strip | >99% raw HTML chars | Compute only |
| Within-page line dedupe | Repeated blocks on same PDP | Compute only |
| Cross-page frequency (≥5 files) | Product-unique copy | Compute only |
| Word-count window | Noise tokens, long prose | Compute only |
| Regex + ignore-list | Nav, footer, reviews | Compute only |
| Embedding vs seed catalog | Optional prioritization | Embedding API |
| LLM classifier | Ambiguous merchandising text | $ |
At 31,055 pages, 61% of frequency-qualified candidates were dropped by ignore-list rules alone — zero tokens.
Data Structures Worth Implementing
Candidate record (per store)
{
"text": "Only 2 left",
"file_count": 842,
"total_files": 12400,
"file_frac": 0.0679,
"word_count": 4,
"example_occurrences": [["1842", 37], ["1901", 41]],
"llm_is_badge": true
}
Occurrence index (for projection)
{
"StoreA": {
"Only 2 left": [["1842", 37], ["1901", 41], "..."]
}
}
Job-level LLM audit
Log input/output tokens, USD, batch counts, and pre-filter drop rates per stage. Without this, you cannot explain why a run cost $0.02 vs $0.31.
Measured Results (Multi-Retailer Validation)
Benchmarks from a seven-store beauty/fashion cohort (June 2026). Numbers are from production batch runs; badge counts below are candidate lines classified as badges after human QA sampling — treat precision as tunable via prompt and thresholds.
Small run — ~200 pages per store cap
| Metric | Value |
|---|---|
| Pages processed | 1,399 |
| Raw HTML | 1.25B characters |
| Markdown after strip | 7.1M characters (0.57% survival) |
| Unique frequency-qualified lines | 2,156 |
| Dropped by ignore-list (pre-LLM) | 1,240 (57%) |
| Sent to LLM classifier | 916 |
| Badge candidates flagged by LLM | 66 lines surfaced for human QA |
| Confirmed net-new badges (after QA) | 15 across 7 stores |
| Total LLM cost | $0.020 |
Full cohort — no page cap
| Metric | Value |
|---|---|
| Pages processed | 31,055 (22× small run) |
| Raw HTML | 27.7B characters |
| Markdown after strip | 203.6M characters (0.74% survival) |
| Unique frequency-qualified lines | 71,013 |
| Dropped by ignore-list (pre-LLM) | 43,193 (61%) |
| Sent to LLM classifier | 27,820 |
| Confirmed net-new badges (after QA) | 15 high-confidence labels for catalog enrichment |
| Total LLM cost | $0.31 |
Key observation: Pages grew 22×; LLM cost grew 15×. Cost per page falls as corpus size increases — the opposite of per-page LLM extraction.
Classifier quality (offline, text-only)
On a class-balanced held-out set of 128 manually labeled short lines (mix of badges and hard negatives — nav text, product copy, policy lines):
| Metric | Score |
|---|---|
| Badge vs non-badge accuracy | ~82% |
| Macro-F1 (across badge / nav / product-copy classes) | 0.87 |
| Agreement with per-page baseline classifier | ~87% |
Text-only classification works because badges are short and self-contained — “Only 2 Left” does not need surrounding PDP context to be identified. The model only struggles at the margins: vague loyalty lines and short policy summaries that a human reviewer also debates.
Operational Notes
- Batch, not real-time: Full cohorts run in tens of minutes to a few hours depending on fetch parallelism and model latency.
- Cached pages: Jobs read from crawl cache URLs; stale cache means stale discoveries — align cohort date with crawl freshness.
- Async jobs: Submit run → poll status → fetch artifacts (JSON, spreadsheet, occurrence index,
llm_usagesummary). - Human QA loop: Interactive viewer filters by store, file fraction, and LLM flag; reviewers click through to source lines before rule handoff.
- Store coverage: Some stores had sparse cache coverage in test cohorts; always inspect fetch summaries before customer-facing delivery.
Limitations (Be Explicit in Design Reviews)
| Limitation | Impact | Mitigation |
|---|---|---|
| Text-first | Icon-only badges with no text/alt are invisible | DOM heuristics or vision model on candidate regions (future) |
| High-frequency false positives | “Free Returns” repeats like a badge | Ignore-list + LLM + human QA |
| Layout drift | Template strip misses new chrome | Frequency + LLM tail; do not over-trust templates |
| Seed catalog maintenance | Similarity step needs curated known badges | Frequency discovery still finds unknowns |
| Not a replacement for extractors | Discovery output is input to rule authoring | Clear SLA: engineers ship selectors after QA |
| Per-store semantics | “New” means different things by retailer | Never merge corpora across stores before dedupe |
Lessons for Engineering Teams
Match cost to information density. Badges are low-entropy repeated strings; per-page LLM is the wrong unit of work.
Build an occurrence index early. Classification without projection leaves reviewers guessing where a string appeared.
Stack cheap filters aggressively. More than half our candidates never needed an LLM once ignore-lists matured.
Separate discovery from extraction SLAs. Discovery can be daily/weekly batch; extraction must be deterministic and monitored.
Log economics per stage. Frequency drop rate, ignore-list drop rate, embedding count, LLM tokens — otherwise optimization is guesswork.
Prototype per-page, production per-line. v1 validated prompts; v3 validated unit economics.
Conclusion
Product badges look trivial to shoppers but are hostile to traditional scrape-and-forget pipelines: copy changes, components move, and campaigns introduce new labels weekly.
We found a practical middle path:
- Use corpus-wide deduplication and frequency to surface candidate badge text cheaply
- Use embeddings and regex to shrink the candidate set further
- Use an LLM only to disambiguate merchandising labels from nav and product copy
- Use an occurrence index to map each confirmed badge back to every PDP
- Hand confirmed labels to engineers for production extraction rules
The result is a system that scales from stratified pilots to 100,000+ PDP corpora with LLM spend measured in cents to low dollars per run, not tens of dollars per thousand pages.
If you are building similar discovery for urgency tags, social-proof labels, or seasonal merchandising strings, the transferable pattern is simple:
Aggregate repeated text once, classify once, project everywhere.
Architecture validated on large multi-retailer PDP corpora. Metrics rounded for publication; internal run logs retain per-job token and cost audit trails.