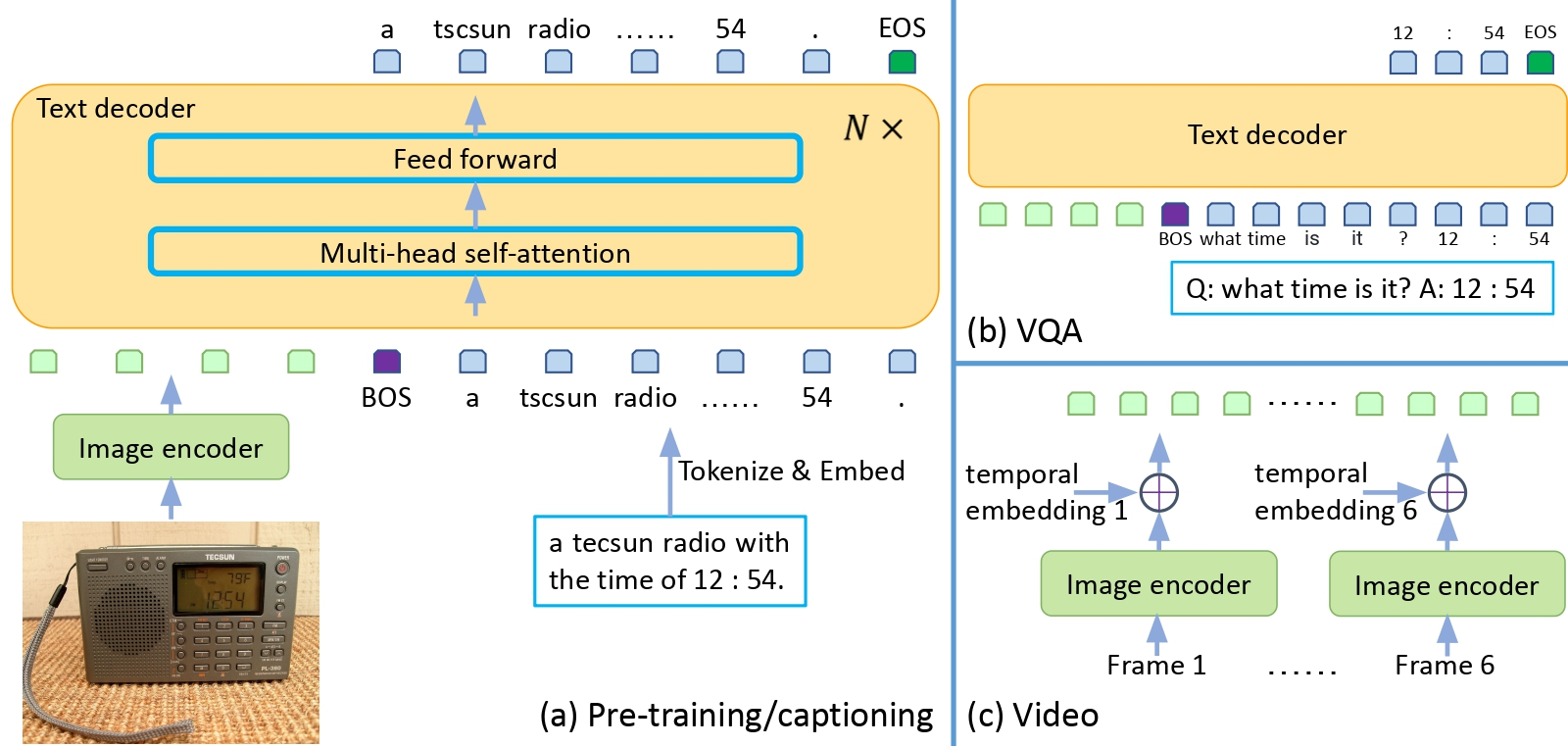
Generative Image to Text - with Single Image Encoder & Single Image Decoder

For Image similarity.
A Tale of 2 U-Nets with Cross-Attention Communication
Multimodal pretraining with text, image, and layout made progress in recent times. One uses 2D positional information i.e. BBoxes to identify the position of text in the layout. For the Large no of digital documents with consistent changes in layouts, existing models are not working.
Fit large model on small GPU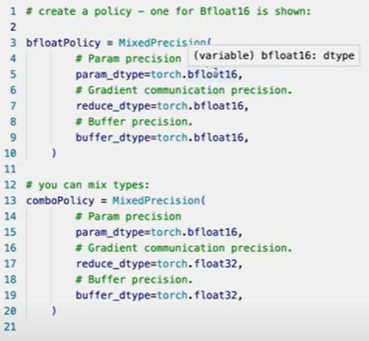
6 modalities embeddings into a common Embedding space. But all these 6 are binded with Image embeddings using image paired data for every single modality as a single shared representation space. hence the name ImageBind. Till now self supervised models like CLIP has only a bi modal space for Text and Image embeddings.
Segmentation using CLIPs Multimodality Embedding space & a Conditinal Decoder
Image & Text as single Multimodality Embedding space.
This is more of my understanding of Transformers rather than the paper summary.