With gan’s world’s first ai generated painting to recent advancement of nvidia
Published:

check out this blog on my medium page here
If you are a Beginner in Deep learning i suggest you check out these blogs.
Data camp Free Deep learning tutorial.  The portrait was offered by Christie’s for sale in New York from Oct 23 to 25 was created with AI algorithm called GAN’s(Generative Adversarial Networks) by the Paris-based collective Obvious, whose members include Hugo Caselles-Dupre, Pierre Fautrel and Gauthier Vernier. The work is estimated to fetch $7,000 to $10,000, according to the auction house.
The portrait was offered by Christie’s for sale in New York from Oct 23 to 25 was created with AI algorithm called GAN’s(Generative Adversarial Networks) by the Paris-based collective Obvious, whose members include Hugo Caselles-Dupre, Pierre Fautrel and Gauthier Vernier. The work is estimated to fetch $7,000 to $10,000, according to the auction house.
 Co-founders of Obvious; Pierre Fautrel, Gauthier Vernier, and Hugo Caselles-Dupré. Courtesy of Ovious. To the surprise this was sold at auction for 4300% of its estimated price to an anonymous telephone bidder. It’s the first auction for an AI-generated portrait.
Co-founders of Obvious; Pierre Fautrel, Gauthier Vernier, and Hugo Caselles-Dupré. Courtesy of Ovious. To the surprise this was sold at auction for 4300% of its estimated price to an anonymous telephone bidder. It’s the first auction for an AI-generated portrait.
The AI-generated “Portrait of Edmond Belamy” depicts a slightly blurry chubby man in a dark frock-coat and white collar, and his off-centre position leaves enough white space to show the artist’s signature as “min G max D Ex[log(D(x))] + Ez[log(1-D(G(z)))] after a section of the algorithm’s code which is the loss function of the original GAN model.
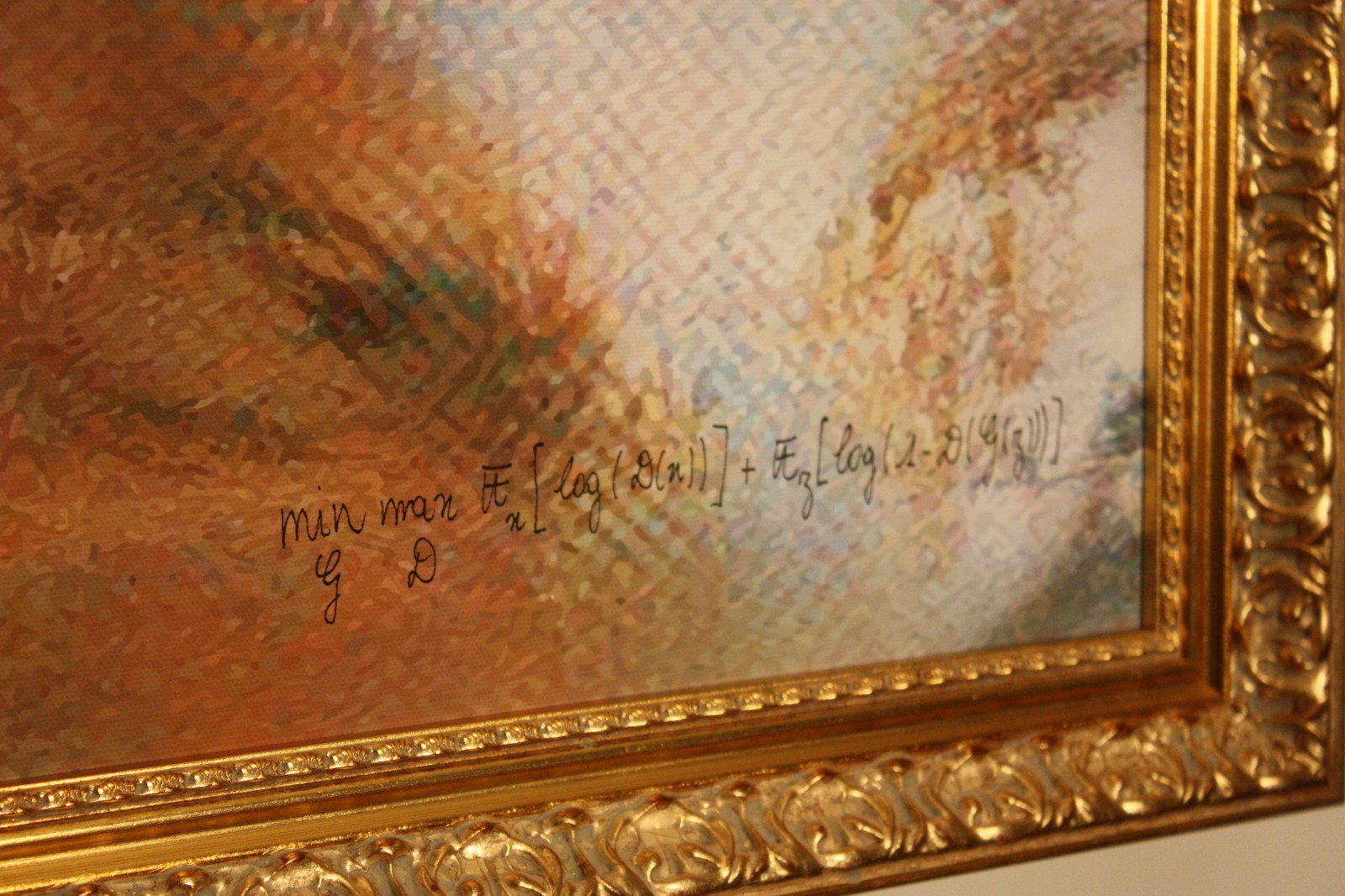 The signature on “Le Comte de Belamy”. It is a reference a core component of the algorithm. and also they added We chose the name “Belamy” to make a reference to the creator name of GANs, I. Goodfellow, that roughly translate to “Bel ami” in French.
The signature on “Le Comte de Belamy”. It is a reference a core component of the algorithm. and also they added We chose the name “Belamy” to make a reference to the creator name of GANs, I. Goodfellow, that roughly translate to “Bel ami” in French.  Ian goodfellow, the man who gave machines the gift of imagination. tataa ! stroy time.
Ian goodfellow, the man who gave machines the gift of imagination. tataa ! stroy time.
One night in 2014, Ian Goodfellow went drinking to celebrate with a fellow doctoral student who had just graduated. At Les 3 Brasseurs (The Three Brewers), a favorite Montreal watering hole, some friends asked for his help with a thorny project they were working on: a computer that could create photos by itself.
Researchers were already using neural networks, algorithms loosely modeled on the web of neurons in the human brain, as “generative” models to create plausible new data of their own. But the results were often not very good: images of a computer-generated face tended to be blurry or have errors like missing ears. The plan Goodfellow’s friends were proposing was to use a complex statistical analysis of the elements that make up a photograph to help machines come up with images by themselves. This would have required a massive amount of number-crunching, and Goodfellow told them it simply wasn’t going to work.
But as he pondered the problem over his beer, he hit on an idea. What if you pitted two neural networks against each other? His friends were skeptical, so once he got home, where his girlfriend was already fast asleep, he decided to give it a try. Goodfellow coded into the early hours and then tested his software. It worked the first time.
What he invented that night is now called a GAN, or “generative adversarial network.” The technique has sparked huge excitement in the field of machine learning and turned its creator into an AI celebrity.
Mario Klingemann is considered a pioneer in the field of neural networks, computer learning, and AI art. Klingemann agrees that the portrait sold at Christie’s doesn’t necessarily represent anything new or groundbreaking. “In the case of Obvious, for me, that is kind of the most basic way of doing it. Throw a few thousand paintings in a folder, take default parameters, train it, and have it generate lots of variations, and then pick the ones that for whatever reason you think are shareable with the world”, he says. “In this case, It’s more like an Instagram filter”.  Mario Klingemann photographed by Alberto Triano. Image courtesy of the artist. Explaining GANs, Klingemann is keen to stress that “these models do not have any intention to be creative”. Amongst the community of coders and artists who use GANs for creative purposes, they’re simply a tool or a medium. “When you work with oil paint, you work with your brushes and your media and in some sense, the pigments and the material still have their own behavior”, Klingemann explains.
Mario Klingemann photographed by Alberto Triano. Image courtesy of the artist. Explaining GANs, Klingemann is keen to stress that “these models do not have any intention to be creative”. Amongst the community of coders and artists who use GANs for creative purposes, they’re simply a tool or a medium. “When you work with oil paint, you work with your brushes and your media and in some sense, the pigments and the material still have their own behavior”, Klingemann explains.
The more measured among the critics also point out that ‘Obvious’, the trio responsible for the portrait, used a pre-existing code designed by 19-year old Robbie Barratt, which was available for download on the hosting website, GitHub.
The artwork was produced as an experiment “in the interface between art and artificial intelligence,” Christie’s said on its website. It was among several portraits produced by AI, all of them arranged in a fictitious Belamy family tree, including Baron de Belamy in a military sash and a countess in pink silks.
Take a look at the some more AI generated portraits of belamy family using GAN’s below. 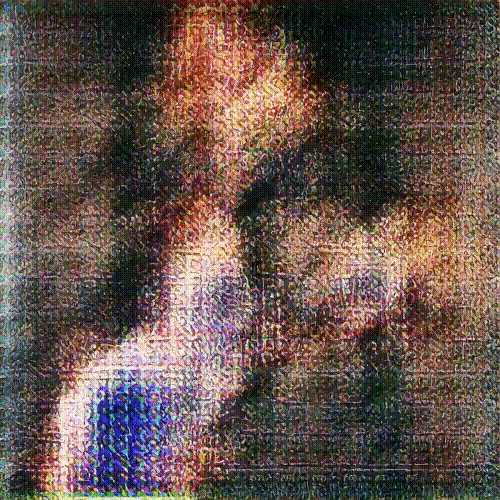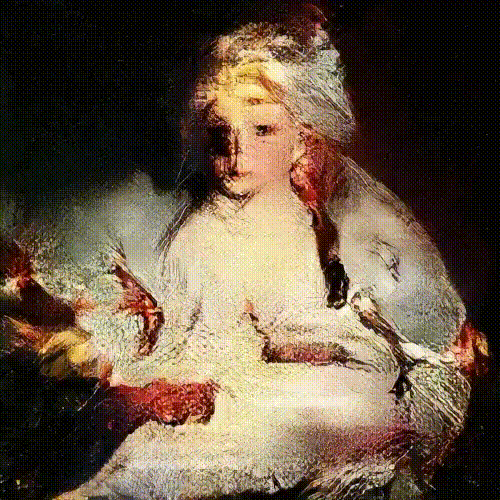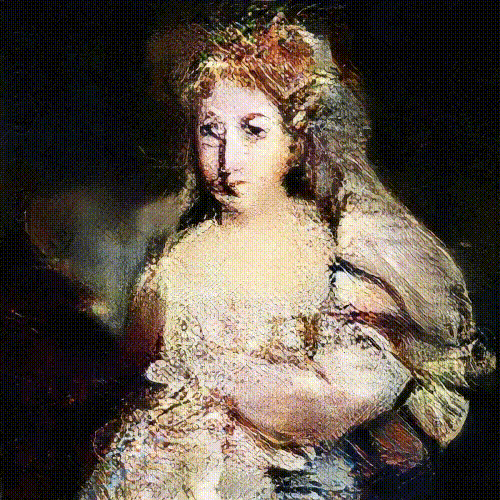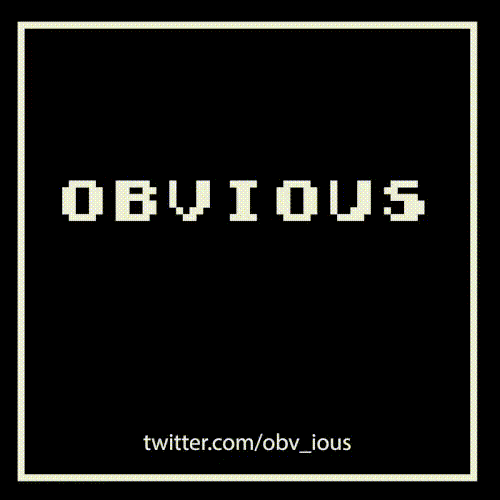 learning from thousands of portraits
learning from thousands of portraits  La Comtesse De Belamy
La Comtesse De Belamy  Le Comte De Belamy
Le Comte De Belamy
and more here.
Each portrait is a 70x70 cm artwork, with a golden wooden frame. It is almost similar to a portrait that you would see in a classical museum. The difference is, it was generated by an algorithm.
They also added this on their blog saying “In late 2017, a “Machine Learning for Creativity and Design” Workshop was organized at the most prestigious Machine Learning conference in the world: NIPS. Lots of submissions included work with GANs. The second edition of this workshop is to appear in December 2018”.
The algorithms involved take input data and recast it as vectors in something called Latent Space. Here, all data is of a similar nature, whether it be images, text, music, or any other material. Because of this zero-level of interpretation, the model can be a kind of ‘Universal Translator’, and cross boundaries that humans could not. These processes will then inspire and inform artists in entirely new ways, allowing them to create completely original artworks.
The AI method is called ‘generative adversarial network’ or GAN, and involves a two-part algorithm. Caselles-Dupré, quoted on the website, said the two parts are the Generator and the Discriminator.
First, a set of 15,0000 portraits painted between the 14th and 20th Centuries was fed into a computer. Then the Generator made a new image based on that set, and the Discriminator tried to spot the difference between a human-made image and one created by the Generator.
“The aim is to fool the Discriminator into thinking that the new images are real-life portraits,” Caselles-Dupré said.
The basic idea of a GAN is that you train a network to look for patterns in a specific dataset (like pictures of kitchen or 18th century portraits) and get it to generate copies. Then, a second network called a discriminator judges its work, and if it can spot the difference between the originals and the new sample, it sends it back. The first network then tweaks its data and tries to sneak it past the discriminator again. It repeats this until the generator network is creating passable fakes. Think of it like a bouncer at a club: sending your drunk friend away until they act sober enough to get in. 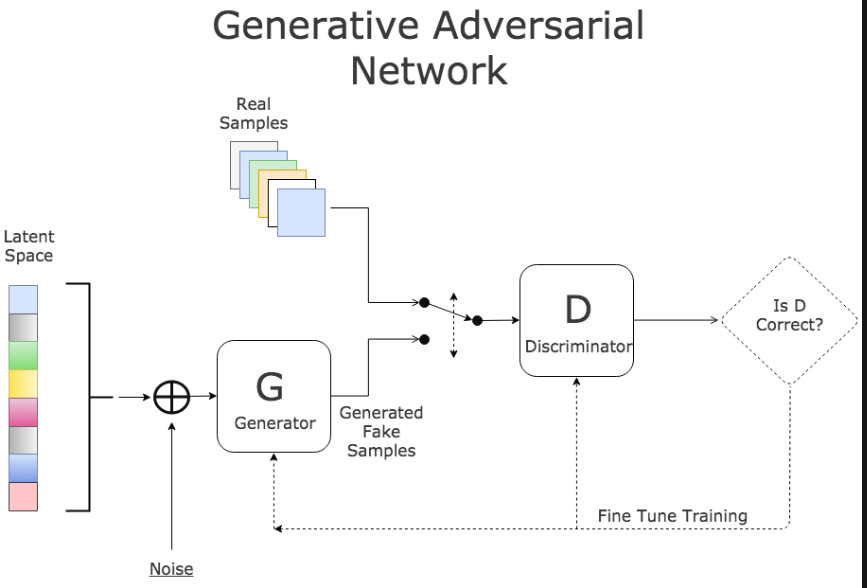 The first neural net is called the Discriminator (D) and is the net that has to undergo training. D is the classifier that will do the heavy lifting during the normal operation once the training is complete. The second network is called the Generator (G) and is tasked to generate random samples that resemble real samples with a twist rendering them as fake samples.
The first neural net is called the Discriminator (D) and is the net that has to undergo training. D is the classifier that will do the heavy lifting during the normal operation once the training is complete. The second network is called the Generator (G) and is tasked to generate random samples that resemble real samples with a twist rendering them as fake samples.
As an example, consider an image classifier (D) designed to identify a series of images depicting various animals or birds or things . Now consider an adversary (G) with the mission to fool (D) using carefully crafted images that look almost right but not quite. This is done by picking a legitimate sample randomly from training set (latent space) and synthesiging a new image by randomly altering its features (by adding random noise). As an example, G can fetch the image of a cat and can add an extra eye to the image converting it to a false sample. The result is an image very similar to a normal cat with the exception of the number of eye. 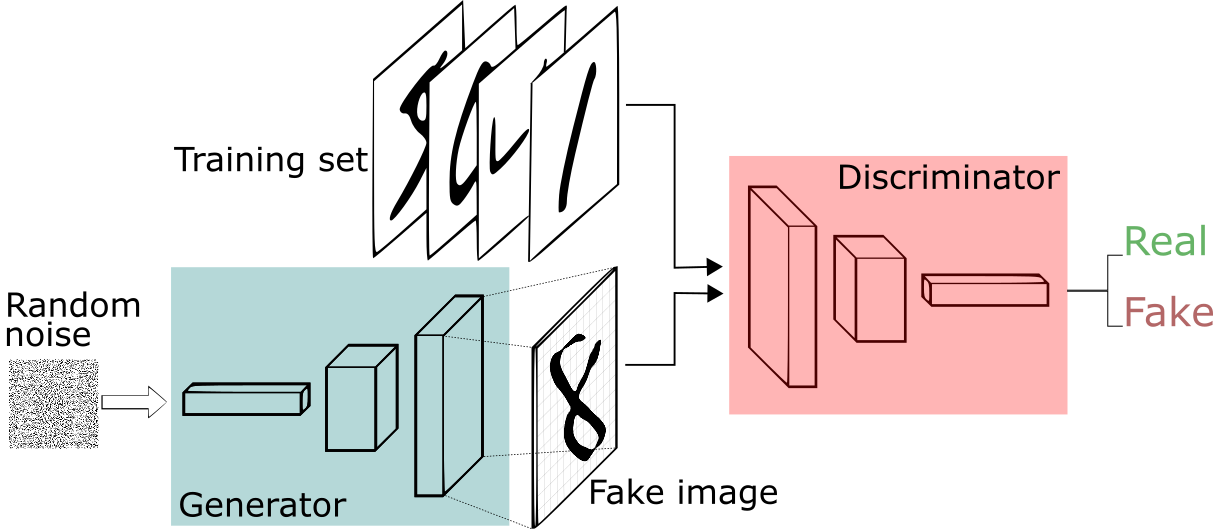 During training, D is presented with a random mix of legitimate images from training data as well as fake images generated by G. Its task is to identify correct and fake inputs. Based on the outcome, both machines try to fine-tune their parameters and become better in what they do. If D makes the right prediction, G updates its parameters in order to generate better fake samples to fool D. If D’s prediction is incorrect, it tries to learn from its mistake to avoid similar mistakes in the future. The reward for net D is the number of right predictions and the reward for G is the number D’s errors. This process continues until an equilibrium is established and D’s training is optimized.
During training, D is presented with a random mix of legitimate images from training data as well as fake images generated by G. Its task is to identify correct and fake inputs. Based on the outcome, both machines try to fine-tune their parameters and become better in what they do. If D makes the right prediction, G updates its parameters in order to generate better fake samples to fool D. If D’s prediction is incorrect, it tries to learn from its mistake to avoid similar mistakes in the future. The reward for net D is the number of right predictions and the reward for G is the number D’s errors. This process continues until an equilibrium is established and D’s training is optimized.
FOR MATH folks:
Here I would like to explain the maths behind the generative adversarial network framework.
Before we start examining GANs closely, let us first review two metrics for quantifying the similarity between two probability distributions.
(1) KL (Kullback–Leibler) divergence measures how one probability distribution p diverges from a second expected probability distribution q. 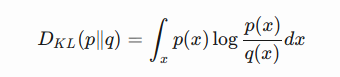 D KL←subscirpt achieves the minimum zero when p(x) == q(x) everywhere.
D KL←subscirpt achieves the minimum zero when p(x) == q(x) everywhere.
It is noticeable according to the formula that KL divergence is asymmetric. In cases where p(x) is close to zero, but q(x) is significantly non-zero, the q’s effect is disregarded. It could cause buggy results when we just want to measure the similarity between two equally important distributions.
(2) Jensen–Shannon Divergence is another measure of similarity between two probability distributions, bounded by [0,1]. JS divergence is symmetric and more smooth. Check this Quora post if you are interested in reading more about the comparison between KL divergence and JS divergence.
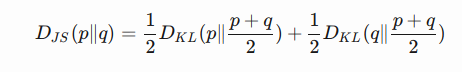 now given,
now given, 
optimal value for D?
Now we have a well-defined loss function. Let’s first examine what is the best value for D. 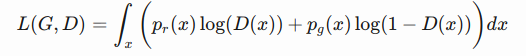 Since we are interested in what is the best value of D(x) to maximize L(G,D), let us label
Since we are interested in what is the best value of D(x) to maximize L(G,D), let us label 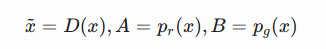 And then what is inside the integral (we can safely ignore the integral because x is sampled over all the possible values) is:
And then what is inside the integral (we can safely ignore the integral because x is sampled over all the possible values) is: 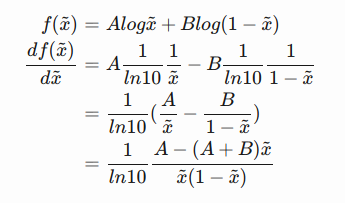

global optimal:
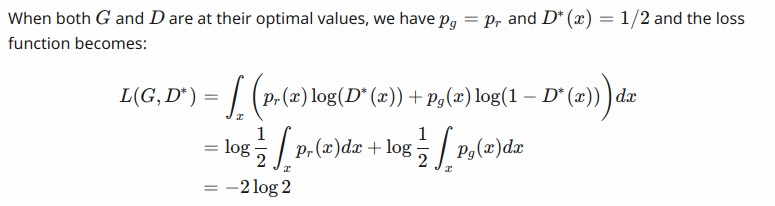
loss function represent:
According to the formula listed in the above, JS divergence between pr and pg can be computed as: 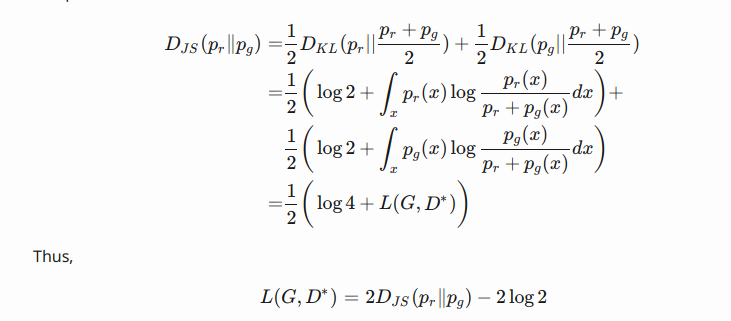 for more check out for math behind gan’s in reference section.
for more check out for math behind gan’s in reference section.
Still if you didn’t get what this GANs is, I suggest you please check out this one.
after that the below one blow your mind.
Here you can visualise this how this works in realtime with the pretrained data. This makes everything sense to you . an awesome website. dont miss to check out this link. because this teaches you more than the theory here. 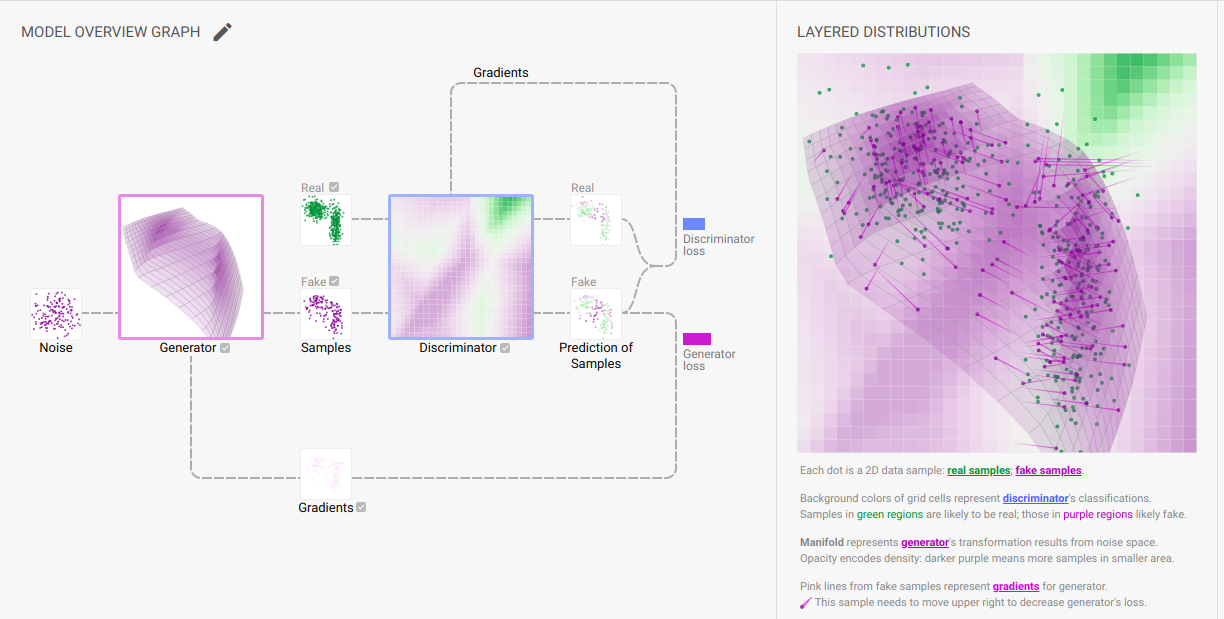 on the other hand this is from the Generative Learning Algorithm lecture of Andrew Ng is
on the other hand this is from the Generative Learning Algorithm lecture of Andrew Ng is
| Algorithms that try to learn p(y | x) directly (such as logistic regression), or algorithms that try to learn mappings directly from the space of inputs X to the labels {0, 1}, (such as the perceptron algorithm) are called discriminative learning algorithms. Here, we’ll talk about algorithms that instead try to model p(x | y) (and p(y)). These algorithms are called generative learning algorithms. For instance, if y indicates whether an example is a dog (0) or an elephant (1), then p(x | y = 0) models the distribution of dogs’ features, and p(x | y = 1) models the distribution of elephants’ features. After modeling p(y) (called the class priors) and p(x | y), our algorithm can then use Bayes rule to derive the posterior distribution on y given x: |
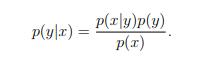 Here, the denominator is given by p(x) = p(x|y = 1)p(y = 1) + p(x|y = 0)p(y = 0) (you should be able to verify that this is true from the standard properties of probabilities), and thus can also be expressed in terms of the quantities p(x|y) and p(y) that we’ve learned. Actually, if were calculating p(y|x) in order to make a prediction, then we don’t actually need to calculate the denominator, since
Here, the denominator is given by p(x) = p(x|y = 1)p(y = 1) + p(x|y = 0)p(y = 0) (you should be able to verify that this is true from the standard properties of probabilities), and thus can also be expressed in terms of the quantities p(x|y) and p(y) that we’ve learned. Actually, if were calculating p(y|x) in order to make a prediction, then we don’t actually need to calculate the denominator, since 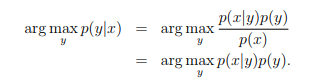

GAN Use Cases
- Text to Image Generation
- Image to Image Translation
- Increasing Image Resolution
- Predicting Next Video Frame for more usecases and applications, please check out this link with more details and explanation written by Deep learning practitioner Jonathan Hui.
Every week, new papers on Generative Adversarial Networks (GAN) are coming out and it’s hard to keep track of them all, not to mention the incredibly creative ways in which researchers are naming these GANs!
So, here’s the current and frequently updated list, where you got nearly a thousand of them.  As i am new to Deep learning and especially to GAN’s this is what all i could able to understood up to now. if any one interested to implement GAN’s , then please check out these repositories
As i am new to Deep learning and especially to GAN’s this is what all i could able to understood up to now. if any one interested to implement GAN’s , then please check out these repositories
- Generative Adversarial Networks implemented in PyTorch and Tensorflow
- Deep Convolution Generative Adversarial Networks
- Image to Image translation in python
- CycleGAN’s
- TLGAN’s Use supervised learning to illuminate the latent space of GAN for controlled generation and edit below
to know more or to know people who are best in Machine learning and well known throught out the world check out this blog on my medium page here
Thank you
Thank you for landing up on this page.