Gpu understanding
GPU:
Get complete GPU driver information here.
Below are some of the well know GPU providers. | https://jarvislabs.ai/pricing/ | https://www.e2enetworks.com/pricing | Runpod | | --- | --- | --- | | https://fullstackdeeplearning.com/cloud-gpus/ | https://lambdalabs.com/gpu-benchmarks | Vast.ai | | https://www.paperspace.com/pricing?_gl=11eg3zpd_gcl_au*MTM5MTExMzc5MC4xNjg1MDIxMzI2 | https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/ | |
Remember: Google colab & Kaggle offers free GPU of 16GB, which is Enough for Most experiments and Quick demos.
Before Deciding to select a provider, Go through Below link to know more about: - Types of GPUs available - Their Memory, VRAM, Storage - Cost and more
link here
NOTE: What’s so expensive per an hour might not be expensive for experiment.
Different GPU architectures like Kepler, Pascal, Volta, Turing, Ampere with different products like K80, P100, …. A6000. Tensor TFLops has Mixed precision, means 16bit+32bit precision in tensors.
Knowing GPU:
GPUs- knowing hardware better has helped to fasten the computing in the LLMs recently. Flash Attention is one such discovery.
Data flow: speed increases as we go towards the end of the flow.
Hardware → Ram → L2/L3 cache →L1 cache/registers in CPU(these are also called onchip memory) → GPU
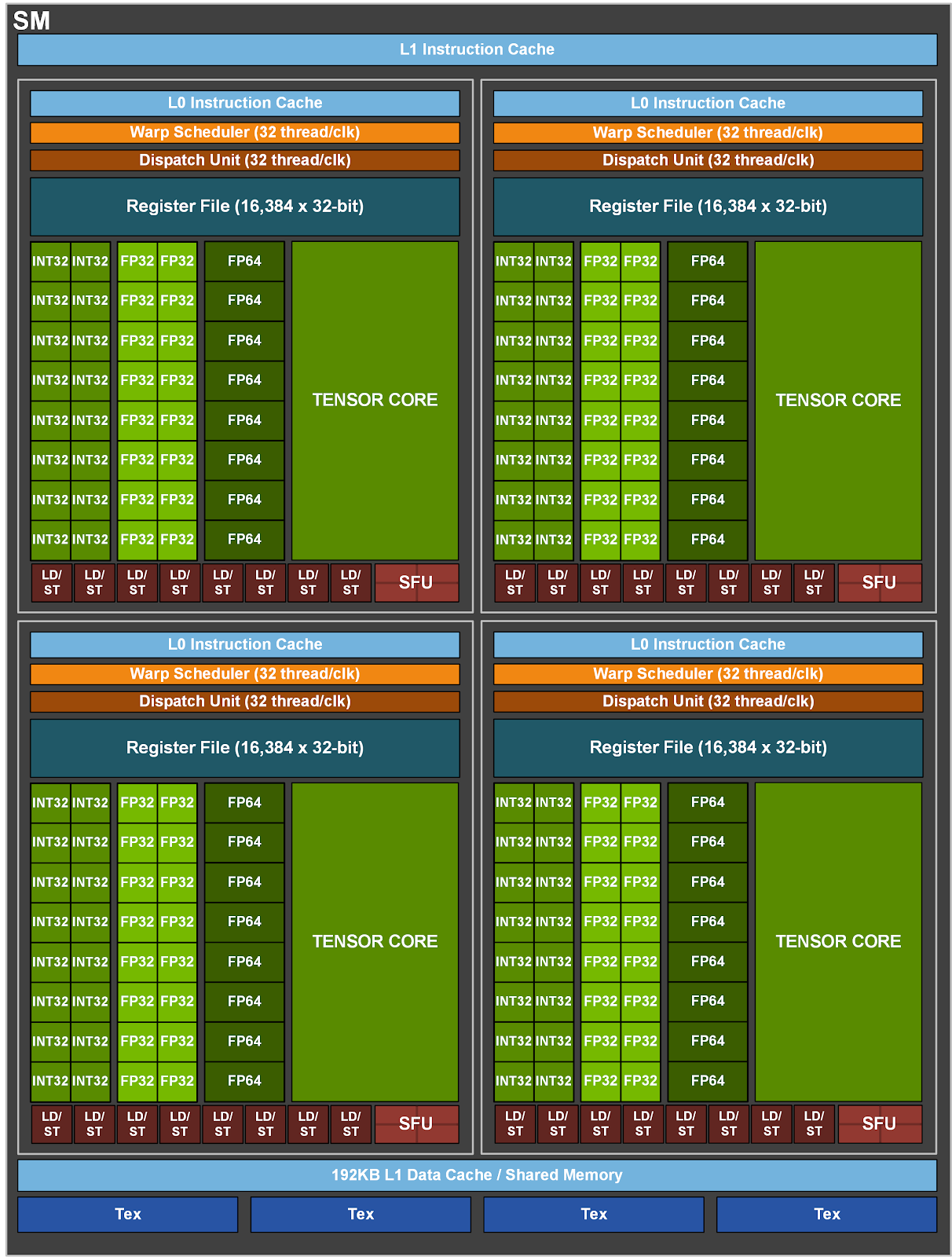
Let's dig one step ahead in GPU as well. The below is how GPU looks.

Tensor cores specialized in matrix multiplication. Cuda cores are from Nvidia. A group of threads is called Threadblock/warps. The warp scheduler handles thread allocation.
1ghz mean = 10^9 operations/cycles per second.
Tensor cores are so fast that they are always idle for half of the time. Researchers found that while training GPT3, they saw tensor cores being idle for half of the time.
A100 is implemented with HBM(High bandwidth technology) by ordering GPU stacks vertically. each GPU stack has 16GB. so 5Stacks*16GB=80GB
FLOPS: Floating operations per second.
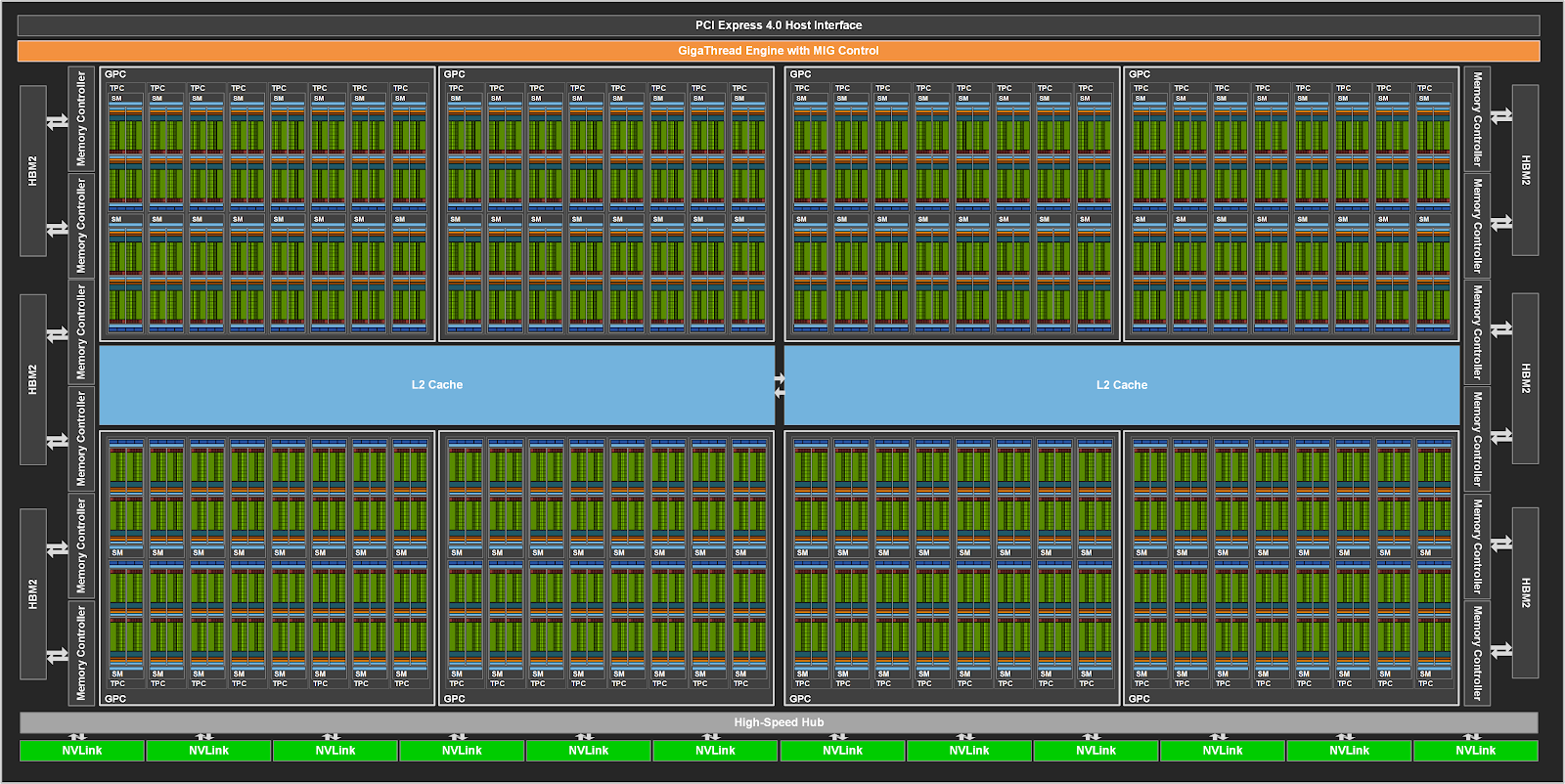
A100 Architecture:
Each Green block is one SM(Streaming Multiprocessors)
A more closer look into 1 SM(streaming multiprocessors): we can see L1 cache and L0 cache. we also see Warp Scheduler that schedules Threads properly.