Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
About me
Published:
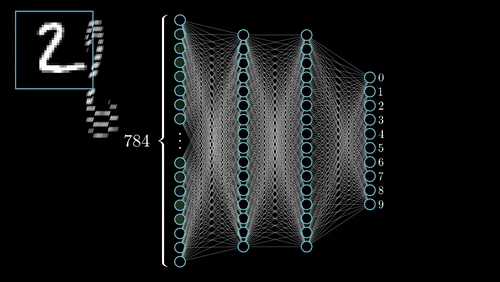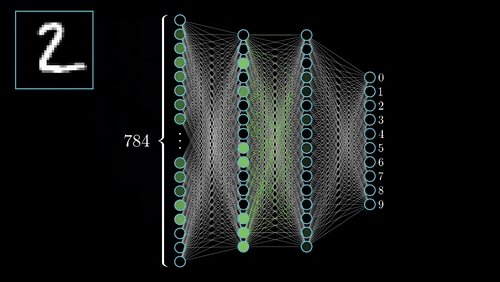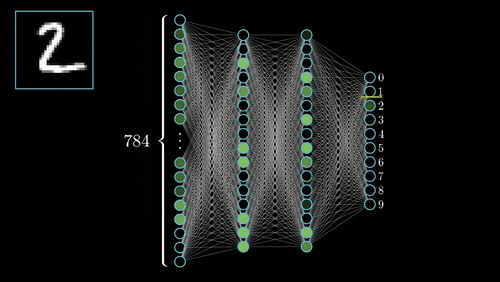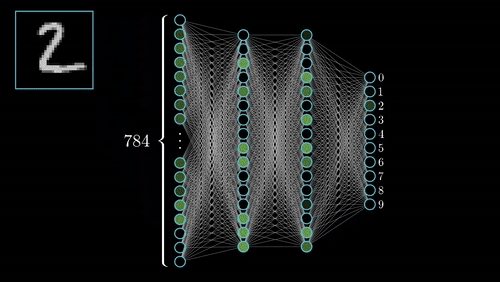
Published:

Published:
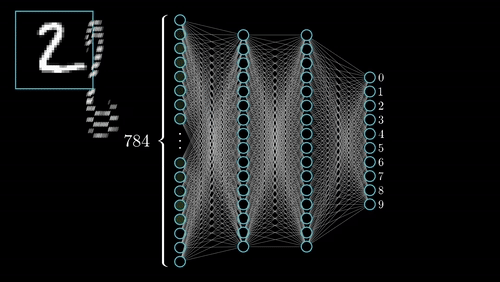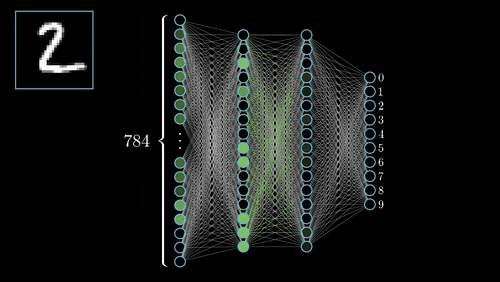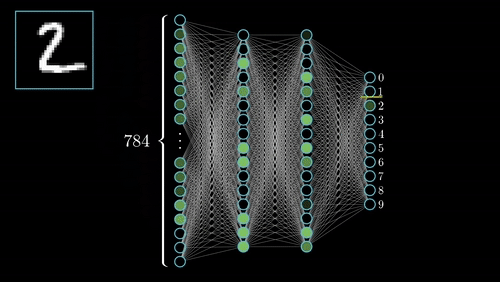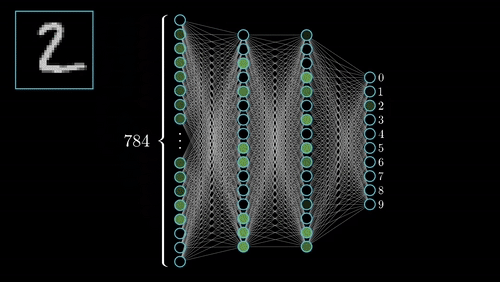
Short description of portfolio item number 1
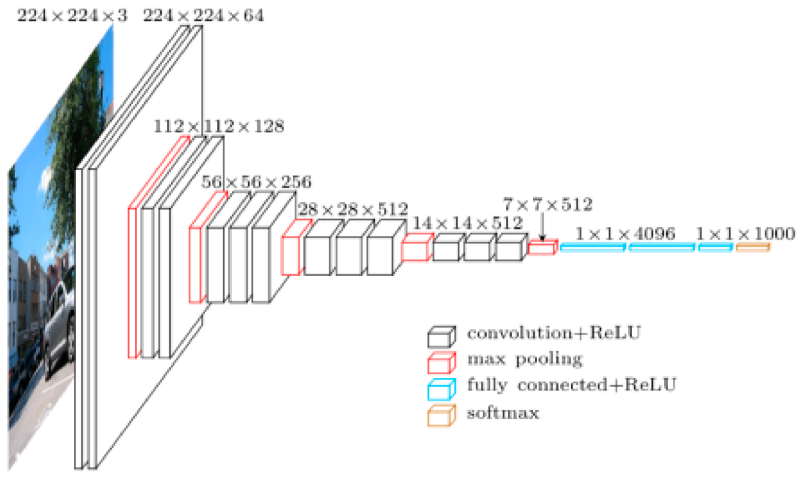
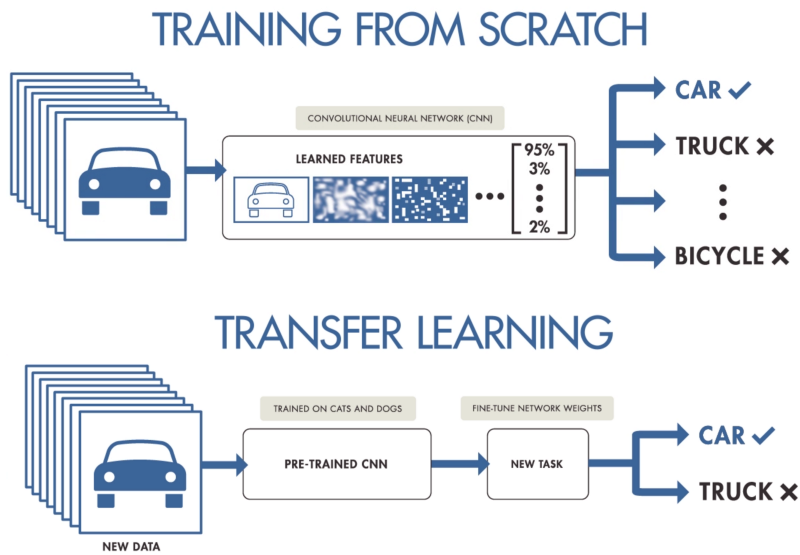
Fit model more than GPU size.
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1). http://academicpages.github.io/files/paper1.pdf
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
Published:
This is more of my understanding of Transformers rather than the paper summary.
Published:
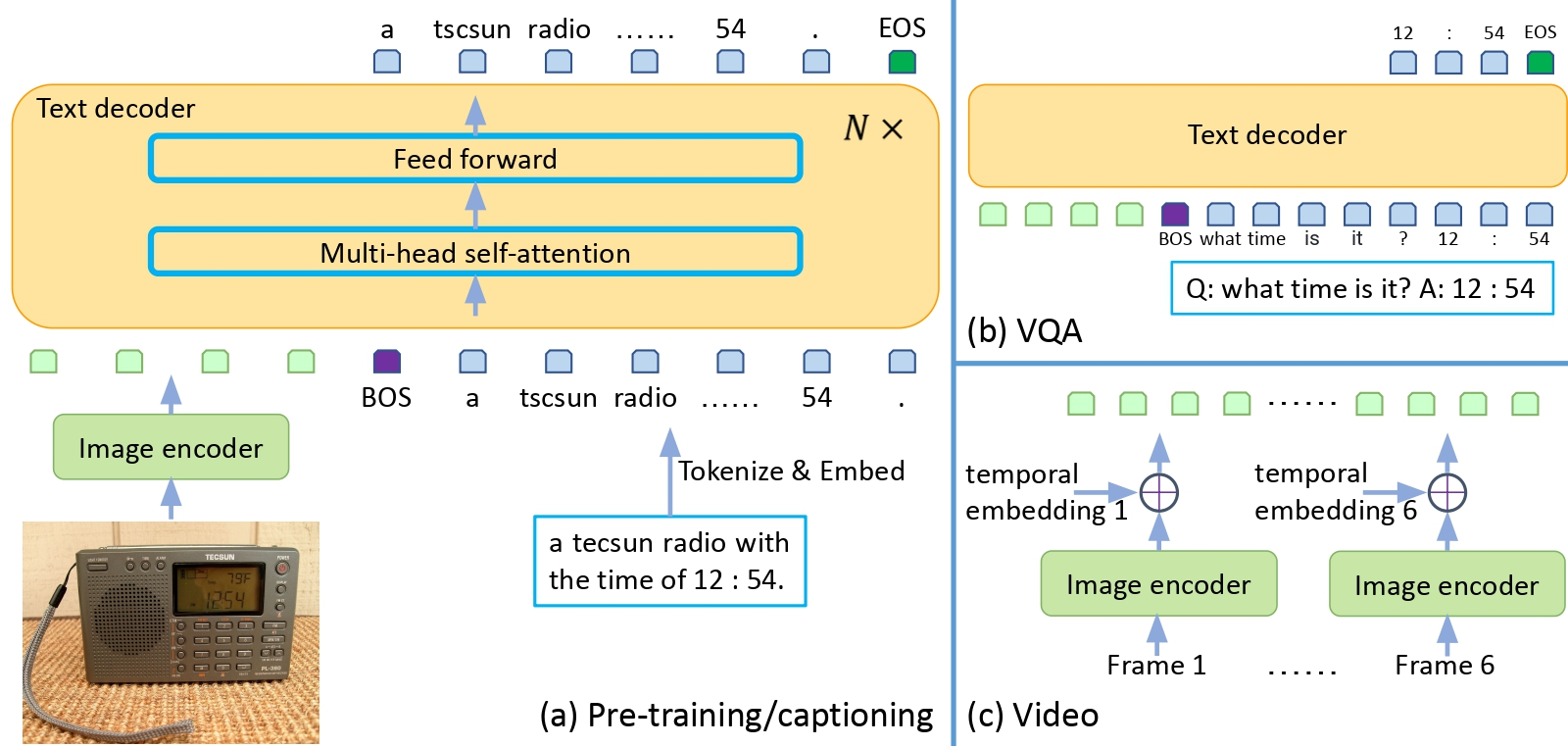
Image & Text as single Multimodality Embedding space.
Published:
Paper here
Published:
Segmentation using CLIPs Multimodality Embedding space & a Conditinal Decoder
Published:
6 modalities embeddings into a common Embedding space. But all these 6 are binded with Image embeddings using image paired data for every single modality as a single shared representation space. hence the name ImageBind. Till now self supervised models like CLIP has only a bi modal space for Text and Image embeddings.
Published:
Fit large model on small GPU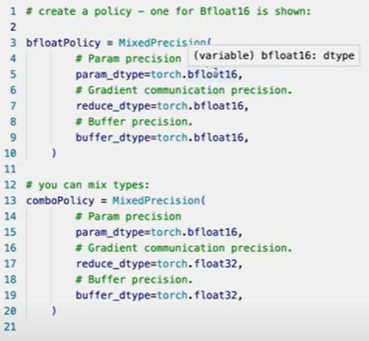
Published:
Multimodal pretraining with text, image, and layout made progress in recent times. One uses 2D positional information i.e. BBoxes to identify the position of text in the layout. For the Large no of digital documents with consistent changes in layouts, existing models are not working.
Published:
A Tale of 2 U-Nets with Cross-Attention Communication
Published:
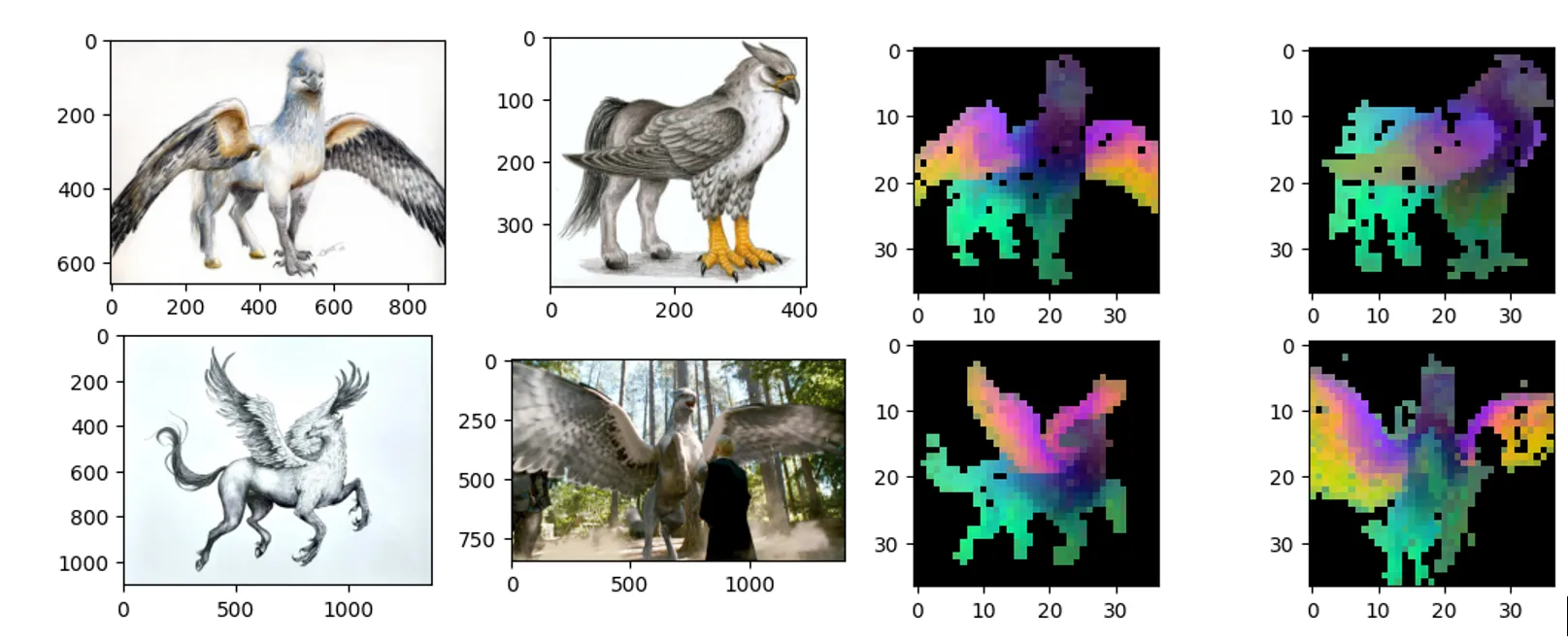
For Image similarity.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.